环境准备
1.搭建三台centos虚拟机,可以搭建一台,然后克隆两台;且三台 虚拟机需要配置静态ip,并能互相ping通。
2.准备hadoop安装包,我的版本是3.2.3,有点高,建议2.7.2左右最好
3.准备jdk8,注意版本要由8u开头,jkd1.8版本左右最好。
4.使用root用户
5.我的三台虚拟机ip分别为:
192.168.100.100 —-hadoop01
192.168.100.101 —-hadoop02
192.168.100.102 —-hadoop03
6.安装组件包括:hadoop,zookeeper,HBase
环境地址
jdk下载链接:https://www.oracle.com/cn/java/technologies/javase/javase8u211-later-archive-downloads.html
hadoop下载链接:https://archive.apache.org/dist/hadoop/common
切记,jdk要下载8u开头的
虚拟机准备
更改三台虚拟机用户名:
第一台为hadoop01,第二台为hadoop02,第三台为hadoop03.
vim /etc/hostname主机ip映射:
vim /etc/hosts
三台虚拟机都需要映射,主要内容为:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.100 hadoop01
192.168.100.101 hadoop02
192.168.100.102 hadoop03
配置安全密钥
首先使用能够上传文件的远程连接工具连接三台虚拟机
在此我选择的是windterm
首先设置公钥
ssh-keygen -t rsa ##回车四次,三台虚拟机都需要配置公钥分发给剩余两台,请注意,分发密钥前请将三台虚拟机公钥都先拷贝。
拷贝公钥:
ssh-copy-id hadoop01
分发密钥:
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh
三台虚拟机创建目录文件
mkdir -p /export/data #创建数据文件
mkdir -p /export/servers #创建软件的安装包
mkdir -p /export/software #创建软件包jdk配置
yum -y install lrzszcd/lrzsz #根据版本定,用来解压 jdk,hadoop压缩包
搜索自带的jdk并删除:
java -version ##查看版本
rpm -qa | grep jdk ##查找jdk配置文件 卸载自带的jdk,所有带open的
一般来讲都只会自带这几个

rpm -e --nodeps+删除的软件包 #nodeps 不考虑依赖关系删除软件包
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
下载jdk
进入创建的/export/software
输入rz
选择对应jdk安装包 切忌,只需要在hadoop01上进行
解压:
tar -zxvf +jdk包名 -C /export/servers
切换到servers目录:
使用mv重命名
mv jdk........jdk #使用mv重命名

配置环境变量:
vim /etc/profile ##打开后到最下面编辑
添加环境变量:
export JAVA_HOME=/export/servers/jdk ##jdk安装路径
export PATH=$PATH:$JAVA_HOME/bin ##路径的主干线
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存退出,然后更新环境变量:
source /etc/profile ##使环境变量生效,重新加载环境变量
java -version ##检查是否安装成功将jdk,profile文件发送给hadoop02,hadoop03,并在另外两台虚拟机上检查jdk版本(java -version)
scp -r /export/servers/jdk hadoop02:$PWD
scp -r /export/servers/jdk hadoop03:$PWD
scp /etc/profile root@hadoop02:/etc/profile
scp /etc/profile root@hadoop03:/etc/profilehadoop安装
下载Hadoop软件包,与jdk安装一样流程,进入创建的 /export/software
rz下载
Tar -zxvf +软件包 -C /export/servers
进入 /export/servers
mv hadoop... hadoop ##重命名hadoop配置hadoop系统环境变量
vim /etc/profile ##在末尾jdk基础上添加内容
添加内容:
export HADOOP_HOME=/export/servers/hadoop ##安装路径
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH ##主配置路径
更新环境变量:
保存,重载环境配置:
source /etc/profile ##保存,重载环境配置
hadoop version ##查看配置是否成功,中间没有-hadoop集群文件配置
| 配置文件名称 | 作用 |
| core-site.xml | Hadoop核心全局配置文件,可在其他配置文件中引用 |
| hadoop-env.sh | 配置hadoop运行所需的环境变量 |
| hdfs-site.xml | HDFS配置文件,继承core-site.xml配置文件 |
| mapred-site.xml | mapreduce配置文件,继承core-site.xml配置文件 |
| slaves | 控制我们的从节点在哪里 datanode nodemanager 在哪些机器上 |
| yam-site.xml | Yarn配置文件,继承core-site.xml配置文件 |
| yarn-env.sh | 配置Yam运行所需的环境变量 |
修改hadoop配置文件
cd /export/servers/hadoop/etc/hadoop/ #接下来六个文件都在此位置更改
1.配置hadoop-env.sh文件
输入 vim hadoop-env.sh
添加内容,并去掉引号:
export JAVA_HOME=/export/servers/jdk ##Jdk的安装路径(大约54行)
2配置core-site.xml文件
输入vim core-site.xml
<!--修改位置位于一对configuration标签中-->
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定-->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在hadoop01机器上-->
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop/tmp</value>
<!--配置Hadoop的临时目录,默认/tem/hadoop-${user.name}-->
</property>
</configuration>3.配置hdfs-site.xml文件
输入vim hdfs-site.xml
<!--依旧一组configuration标签中-->
<configuration>
<!--指定HDFS的数量-->
<property>
<name>dfs.replication</name>
<value>3</value> #服务器数量
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value> #这里改为第二台虚拟机的名字
</property>
</configuration>4.配置mapred-site.xml文件
首先拷贝mapred-site.xml.template文件 命名为mapred-site.xml (低版本需要,3版本以上普遍不存在’mapred-site.xml.template’文件),若不存在’mapred-site.xml.template’文件,直接进入mapred-site.xml文件.
<!--依旧老位置一组configuration表签中更改-->
<configuration>
<!--指定MapReduce运行时的框架,这里指定在YARN上,默认在local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.修改yarn-site.xml文件
输入vim yarn-site.xml
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value> ##写主机名,其他内容不变,建议为主机节点
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>6.配置workers(slaves)文件
3.0版本以前为slaves,3.0以后为workers
vim slaves 2版本
vim workers 3版本后
输入:
hadoop01 ##三个虚拟机主机名
hadoop02
hadoop037.将主节点中配置好的环境变量文件和hadoop目录copy给子节点
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
8.重载环境变量
source /etc/profile9.格式化文件系统
主节点执行
hdfs namenode -format此处会出现很多问题,有些爆红(false)为正常现象,
当此处为successfully差不多成功:

10.root配置环境变量(root用户登录需要在profile内配置一下变量)
添加在hadoop变量后
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
重载:
source /etc/profileHadoop集群测试
1.关闭防火墙,以及开机自启
systemctl stop firewalld
systemctl disable firewalld2.一键脚本开启
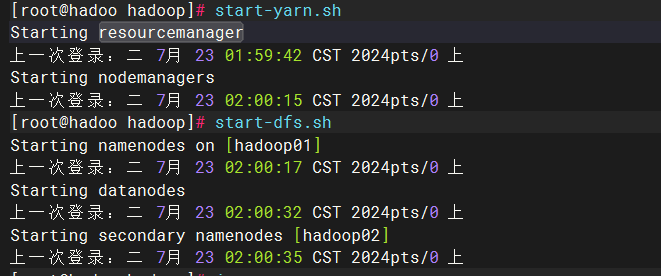
start-dfs.sh ##启动 HDFS 相关服务,如 NameNode 和 DataNode 等
start-yarn.sh ##用于启动 YARN 相关服务,如 ResourceManager 和 NodeManager 等
start-all.sh 开启所有服务
stop-dfs.sh 关闭
stop-yarn.sh正常显示:

3.查看进程
输入命令:jps
##正常会显示:
NameNode:如果是主节点。
DataNode:如果是数据节点。
ResourceManager:如果是资源管理节点。
NodeManager:如果是节点管理器所在节点。4.windows测试
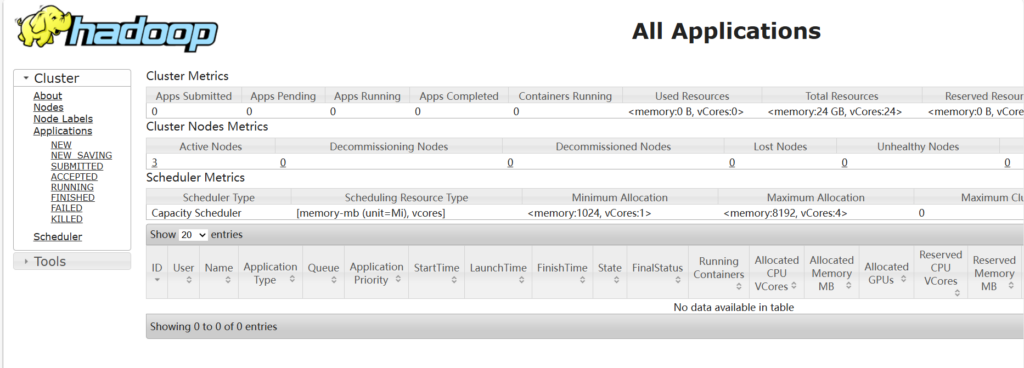
访问50070端口
hadoop01:50070 或者主节点ip:50070 ##请注意,3x版本以上端口号是9870
访问8088端口
格式一样: ip地址或者主机名 +端口号
zookeeper组建安装
准备
1.可以完全紧跟上面操作
2.jdk,hadoop必须已经安装,hadoop集群必须已经启动
3.查看jdk,hadoop版本
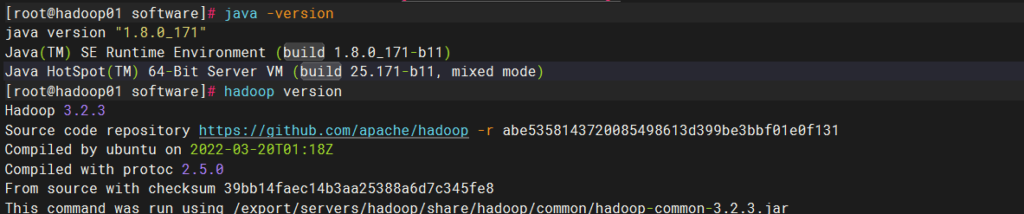
下载zookeeper包
cd /export/software
rz
解压至servers中
tar -zxvf zookeeper包名 -C /export/servers/
修改软件名,在servers目录下
mv 包名 zookeeper357 ,数字为版本号,为了好操作建议该名称
创建数据/日志目录
data数据目录
logs日志目录
修改配置文件
cd /export/servers/zookeeper/conf ##进入zookeeper配置目录
cp cp zoo_sample.cfg zoo.cfg ##复制zookeeper模板配置文件
vim zoo.cfg输入:
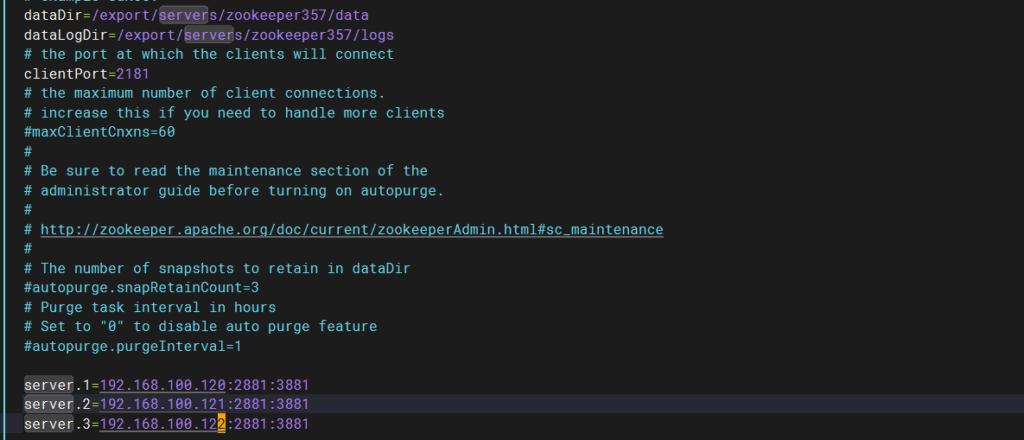
dataDir=/export/servers/zookeeper357/data ##指定zookeeper数据目录,具体为你创建的位置
dataLogDir=/export/servers/zookeeper357/logs ##指定zookeeper日志目录,具体为你创建的位置
server.1=192.168.100.120:2881:3881 ip地址分别为你的三台hadoop的ip地址
server.2=192.168.100.121:2881:3881
server.3=192.168.100.122:2881:3881
##server.n n是一个数字,表示这个是第几号服务器
“=”后面可跟主机地址或者IP地址
2881为集群中从服务器(follower)连接到主服务器(leader)的端口,为主服务器(leader)使用
3881为进行选举(leader)的时使用的端口
具体配置可参考
配置服务器id识别文件
cd /export/servers/zookeeper357/data
创建文件
vim myid
输入1

分发配置文件
返回到 /export/servers 目录下
输入:
scp -r /export/servers/zookeeper357 hadoop02:$PWD
scp -r /export/servers/zookeeper357 hadoop03:$PWD更改hadoop02,hadoop03 中/export/servers/zookeeper357/data/myid文件,分别为2,3


关闭防火墙,要么public端口添加2881/3881端口号

启动测试
切记,请先开启hadoop
cd /export/servers/zookeeper357
输入:bin/zkServer.sh start
与hadoop不同的是开启zookeeper需要开启bin下面的zkServer.sh 我的理解是因为没有配置profile变量么?有知道的大佬给我讲讲

其他两台都要启动,不演示了
查看zookeeper状态
输入:bin/zkServer.sh status
我的leader在hadoop02上,三个节点都要看看,两个follower,一个leader

关闭zookeeper
输入:bin/zkServer.sh stop 三台都要
HBase组件安装
准备
1.可以完全紧跟上面操作
2.jdk,hadoop必须已经安装,hadoop集群必须已经启动
3.查看jdk,hadoop版本
下载hbase包
cd /export/software
rz

解压至servers中
tar -zxvf hbase包名 -C /export/servers/
修改软件名,在servers目录下
mv 包名 hbase

配置环境变量
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export HBASE_HOME=/export/servers/hbase
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
##这里我组合到一起了
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置hbase配置文件
cd /export/servers/hbase/conf hbase的主配置目录
vim hbase-env.sh
export JAVA_HOME=/export/servers/jdk ##jdk路径 大约28行
export HBASE_MANAGES_ZK=false ##不使用自带的zookeeper服务,所以我们要开启我
们自己的zookeeper服务
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" ##大概140行,‘#’去掉,不去掉你陪博主一起装完了,装hive装不了吧,然后快照回来再搞一次~
vim hbase-site.xml
<property>
<name>hbase.cluster.distributed</name> ##选择集群模式,单节点为false,分布式即为true,必须指定的参数
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/export/servers/hbase/hbaseData</value> ##临时文件目录,所以在hbase根目录下需要创建一个,不自带
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:9000/hbase</value> ##数据存放地 需要与Hadoop的hdfs一致,必须要,他给的默认地址每次重启后数据会丢失
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop02,hadoop03</value> ##zookeeper地址
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name> ##zookeeper日志数据等存放地
<value>/export/servers/hbase/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name> ##不指定为false会出现找不到HMaster
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value> ##指定客户端端口
</property>
</configuration>vi regionservers

建立临时数据目录
cd/export/servers/hbase
mkdir hbaseData
分发配置文件
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile ##分发环境配置文件
scp -r /export/servers/hbase hadoop02:$PWD ##前提是要在hbase目录下
scp -r /export/servers/hbase hadoop03:$PWD
集群测试
在hadoop01上执行
执行顺序:
hadoop——zookeeper——hbase
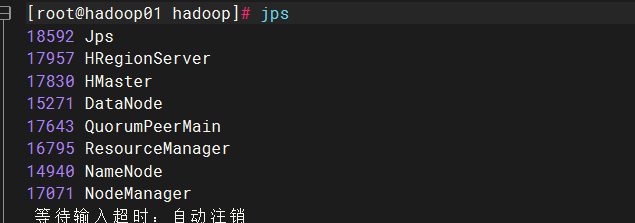
start-hbase.sh
有以下即为正常,此展示主节点
输入:
hbase shell 进入 命令行界面操作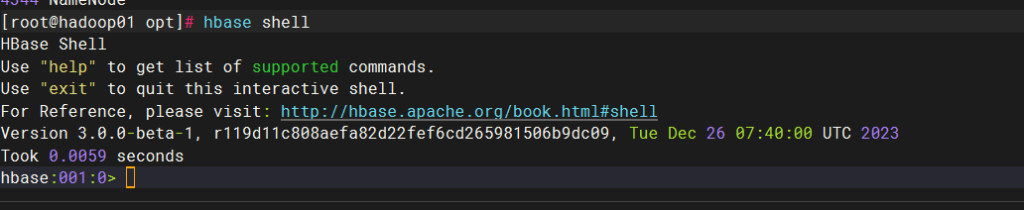
web页面
主节点ip+16010端口,2版本以下为60010端口
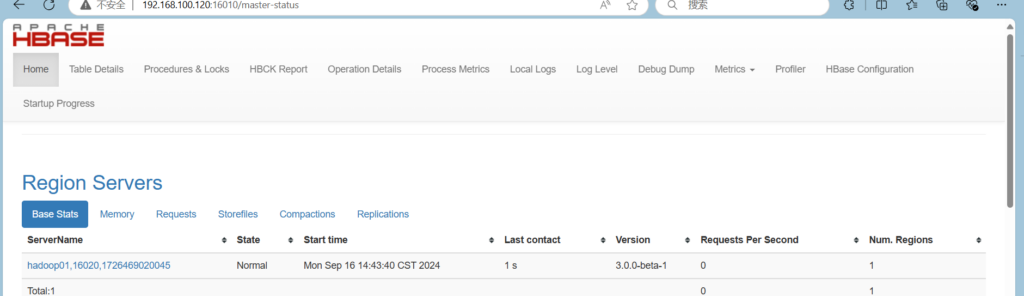
hive组件安装
注意
1.可以完全紧跟上面操作
2.jdk,hadoop必须已经安装,hadoop集群必须已经启动
3.查看jdk,hadoop版本
4.这里展示的hive类似单节点
卸载自带mariadb数据库
输入:
rpm -qa | grep mariadb
有就删除,没有就跳过此步骤


hive安装
上传hive软件包
解压至servers中,并改名hive
设置变量
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export HBASE_HOME=/export/servers/hbase
export HIVE_HOME=/export/servers/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root安装mysql
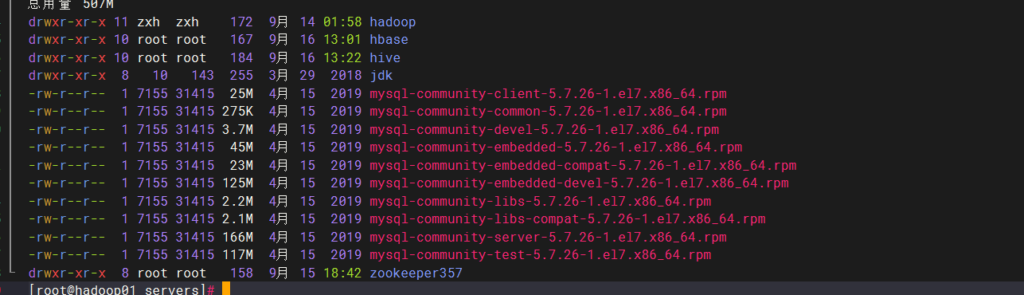
首先上传mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar 上传mysql的bundle安装包

解压至servers
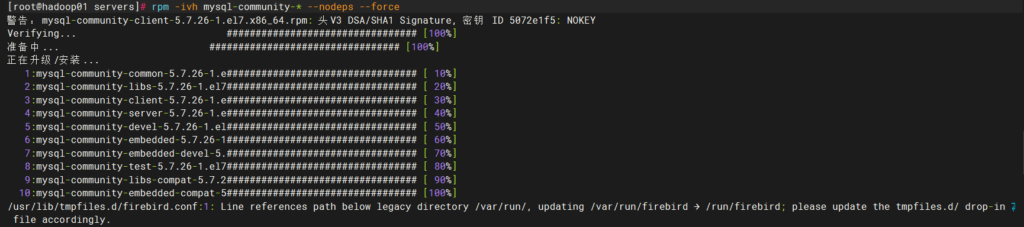
rpm -ivf mysql-community-* –nodeps –force 不加忽视条件安装
开启mysql
systemctl start mysqld
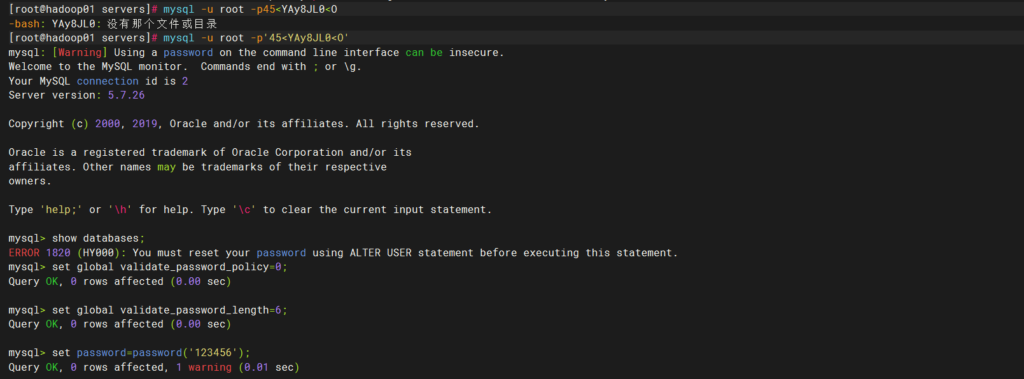
systemctl enable mysqld获取mysql初始密码

使用初始密码登录,可看到无法使用show databases;来查看已有库
设置mysql密码策略等级为0(最低级)
set global validate_password_policy=0;
设置密码长度为6
set global validate_password_length=6;
设置密码为123456
set password=password(‘123456’);
修改权限(允许所有用户连接),在数据库内进行:
update mysql.user set host=’%’ where user=’root’;
也可:
grant all privileges on *.* to ‘root’@’%’ identified by ‘123456’ with grant option
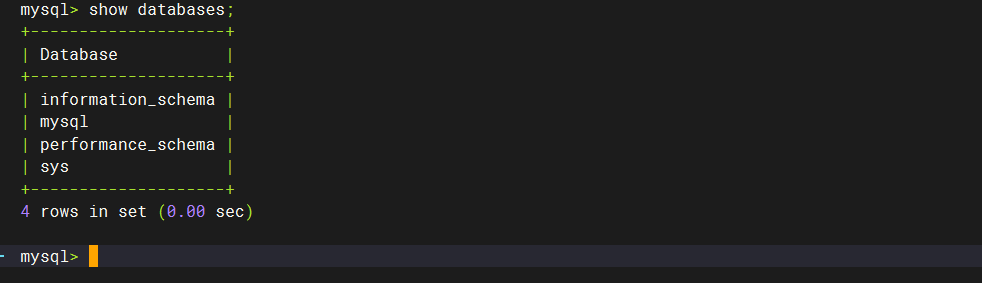
刷新,更新权限
flush privileges;

使用修改后的密码登录,可看到能查看库
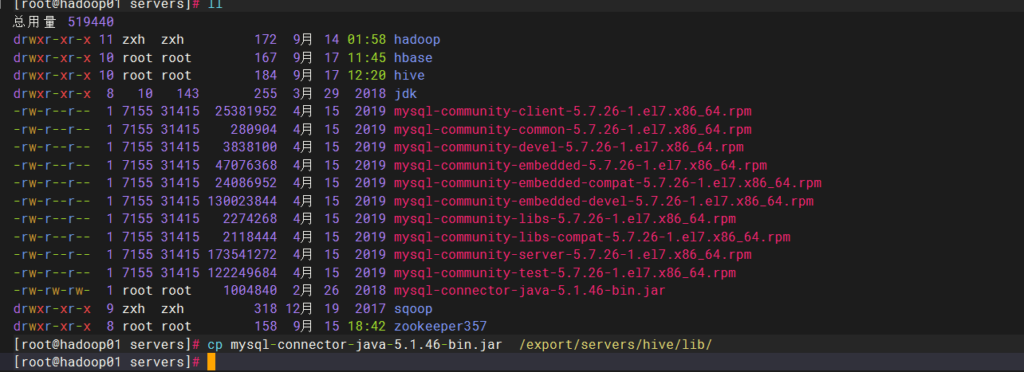
上传mysql-connector-java-5.1.46-bin.jar,并放置在hvie的lib目录下
修改hive配置文件
创建储存文件
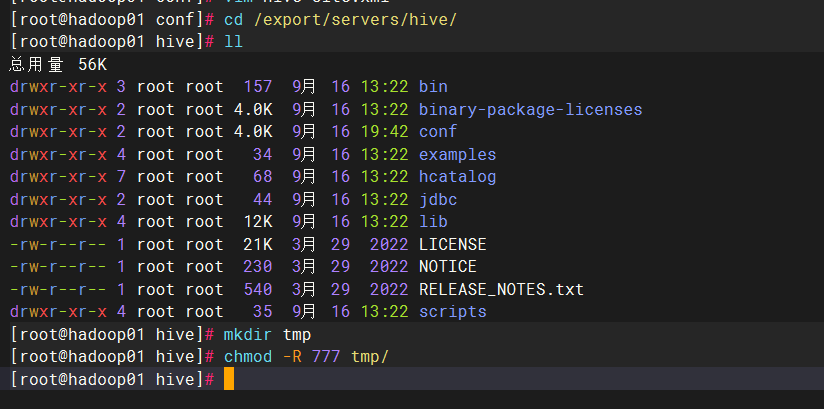
cd /conf
复制模板文件
cp hive-site.template.xml hive-site.xml
vim hive-site,xml
### 配置文件相关,三处
1844 <property>
1845 <name>hive.querylog.location</name>
1846 <value>/export/servers/hive/tmp/hive</value> ##更改此处
1847 <description>Location of Hive run time structured log file</description>
1848 </property>
141 <property>
142 <name>hive.exec.local.scratchdir</name>
143 <value>/export/servers/hive/tmp/hive</value> ##修改此处
144 <description>Local scratch space for Hive jobs</description>
145 </property>
146 <property>
147 <name>hive.downloaded.resources.dir</name>
148 <value>/export/servers/hive/tmp/hive</value> ##zheli
149 <description>Temporary local directory for added resources in the remote file system.</description>
150 </property>
### 数据库相关配置,四处
1100 <property>
1101 <name>javax.jdo.option.ConnectionDriverName</name>
1102 <value>com.mysql.jdbc.Driver</value> ##驱动路径
1103 <description>Driver class name for a JDBC metastore</description>
1104 </property>
582 <property>
583 <name>javax.jdo.option.ConnectionURL</name>
584 <value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value> ##改mysql的地址
585 <description>
586 JDBC connect string for a JDBC metastore.
587 To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
588 For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
589 </description>
590 </property>
1125 <property>
1126 <name>javax.jdo.option.ConnectionUserName</name>
1127 <value>root</value> ##修改为你数据库管理员,默认都是root
1128 <description>Username to use against metastore database</description>
1129 </property>
567 <property>
568 <name>javax.jdo.option.ConnectionPassword</name>
569 <value>123456</value> ##设置的用户密码
570 <description>password to use against metastore database</description>
571 </property>更新
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<!-- 数据库 start -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>mysql连接</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>数据库使用用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>数据库密码</description>
</property>
<!-- 数据库 end -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<description>开启Hive的并发模式</description>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
<description>用于并发控制的锁管理器类</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop01</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>hive开启的thriftServer端口</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<!-- 其它 end -->初始化数据库
建立元数据库
数据库内进行
create database if not exists metastore;初始化
在hive根目录下
bin/schematool -dbType mysql -initSchema -verbose这样才成功

节点分发
分发hive配置文件以及环境变量到hadoop02,hadoop03
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/servers/hive hadoop02:$PWD ##需要到servers目录下
scp -r /export/servers/hive hadoop02:$PWD重载环境变量并查看是否分发成功
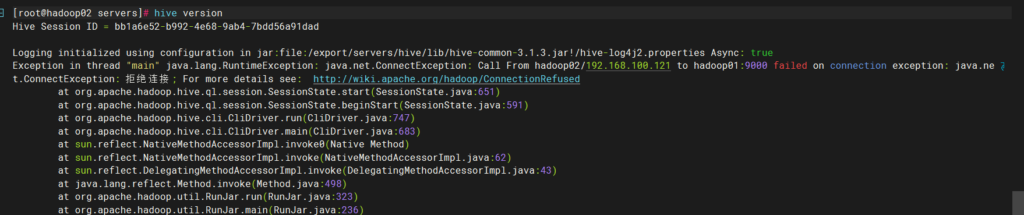
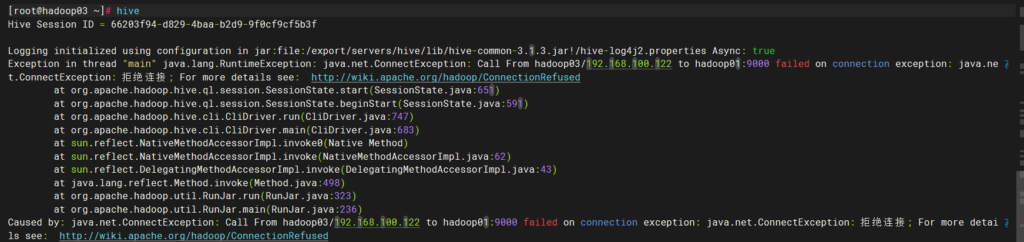
async必须为true,并且有版本号,后面报错正常,因为主节点hadoop没开启
启动与测试
顺序:
hadoop——metastore——hive
首先需要启动hadoop集群,其次开启元数据库,最后开启hive
start-all.sh
hive --service metastore
hive测试
show不出来一律失败

sqoop组件安装
注意
1.可以完全紧跟上面操作
2.jdk,hadoop必须已经安装,hadoop集群必须已经启动
3.查看jdk,hadoop版本
下载sqoop包
老样子
rz
下载到software,解压到servers,mv为sqoop

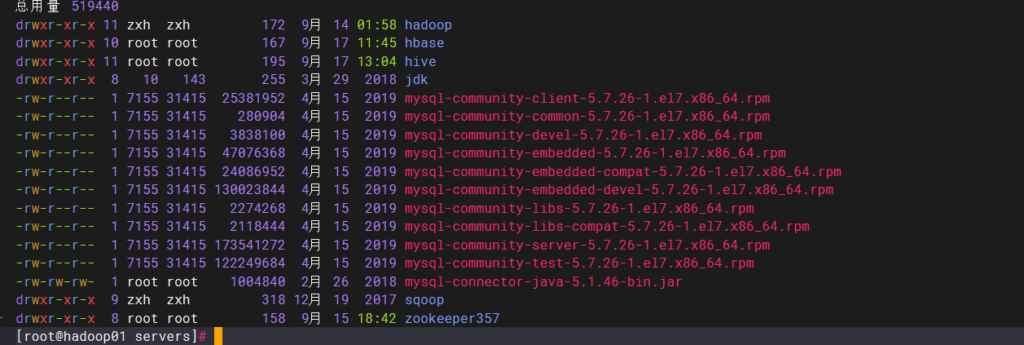
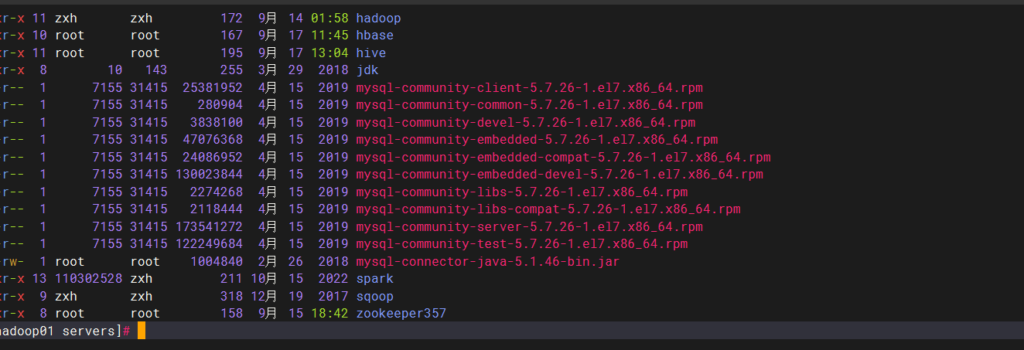
环境变量配置
到目前为止,jdk,hadoop,hbase,hive,zookeeper,sqoop的全部环境变量
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export HBASE_HOME=/export/servers/hbase
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH=$PATH:$HBASE_HOME/bin:$PATH
export SQOOP_HOME=/export/servers/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
export HIVE_HOME=/export/servers/hive
export PATH=$PATH:$HIVE_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置主配置文件
cd/export/servers/sqoop/conf
复制模板文件
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
如果你的hadoop,zookeeper,hive,hbase全都配置了的话,那下面的都需要配置路径
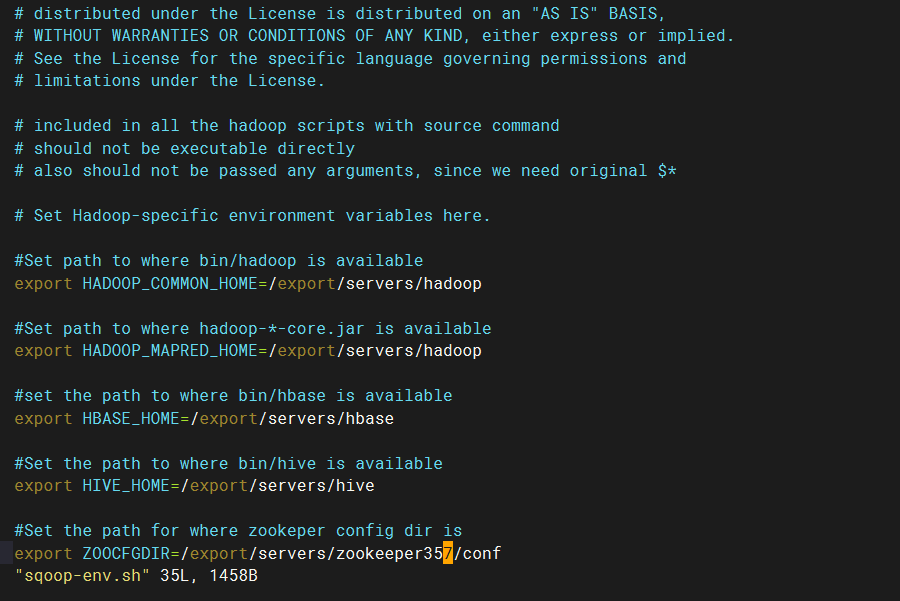
驱动拷贝
拷贝hive,mysql驱动至sqoop

测试
我的有问题,可能是版本问题,之后在全部用老师的,所以这里也先不分发Hadoop02,03了等我搞好了在弄

spark组件安装
注意
1. 可以完全紧跟上面操作
2.jdk,hadoop 必须已经安装,hadoop 集群必须已经启动
3. 查看 jdk,hadoop 版本
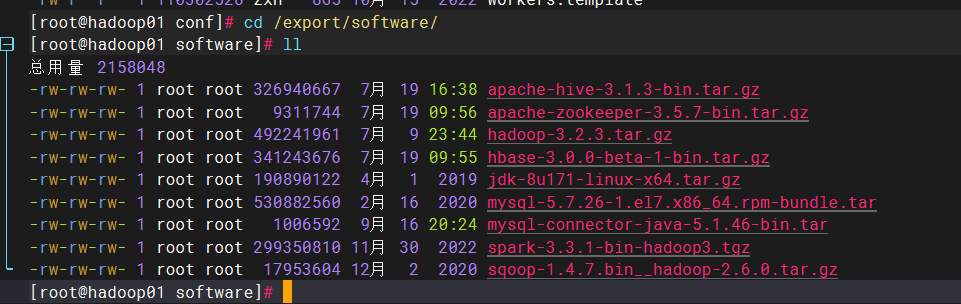
下载spark包
rz
下载到software,解压到servers,mv为spark
配置主配置文件
cd /export/servers/spark/conf
复制spark-env模板文件
scp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/export/servers/jdk ##jdk路径
export SPARK_MASTER_HOST=hadoop01 ##主节点
export SPARK_MASTER_PORT=7077复制workers模板文件
cp workers.template workers 3x版本后,以下slaves
vim workers
hadoop01
hadoop02 ##输入两个从节点
hadoop03
~ 修改环境变量
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin
重载
source /etc/profile
配置分发
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/servers/spark hadoop02:$PWD
scp -r /export/servers/spark hadoop03:$PWD集群测试
cd /export/servers/spark/
bin/spark-shell
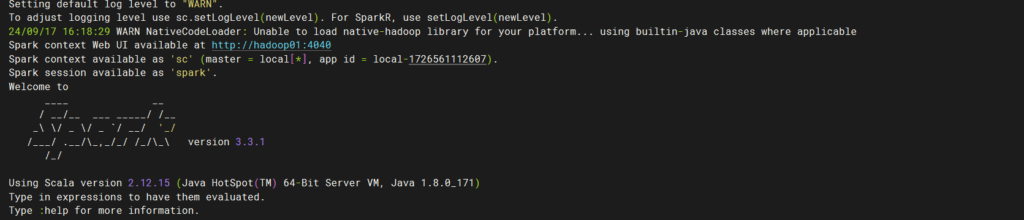
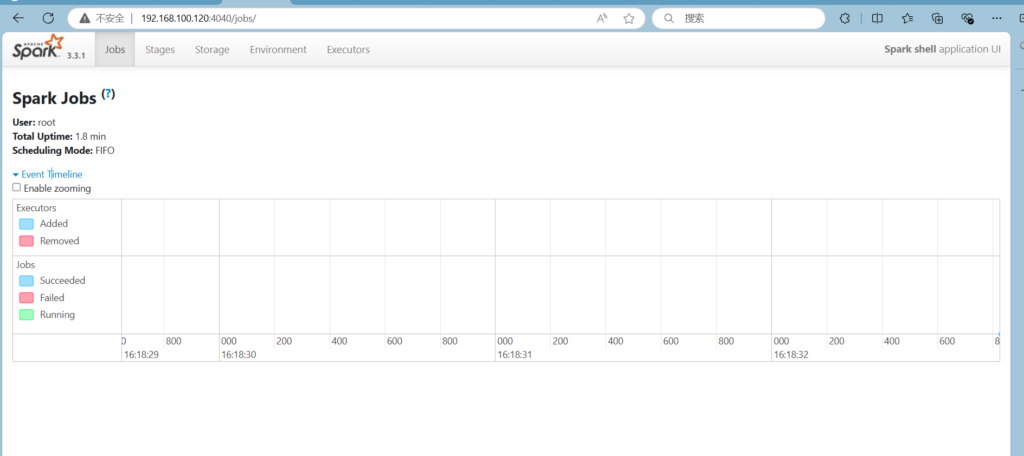
输入http://hadoop01:4040 进入web界面




如果是在脚本中设置,请确保语法正确,例如在Bash中使用 export HADOOP_SQOOP_USER=your_value。